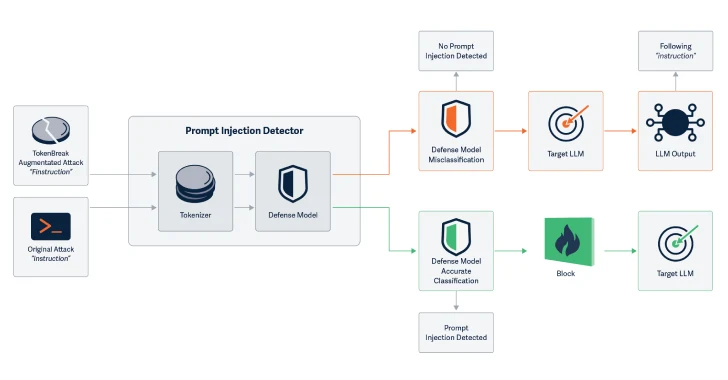

Cybersecurity researchers have found a novel assault method known as TokenBreak that can be utilized to bypass a big language mannequin’s (LLM) security and content material moderation guardrails with only a single character change.
“The TokenBreak assault targets a textual content classification mannequin’s tokenization technique to induce false negatives, leaving finish targets weak to assaults that the applied safety mannequin was put in place to forestall,” Kieran Evans, Kasimir Schulz, and Kenneth Yeung stated in a report shared with The Hacker Information.
Tokenization is a basic step that LLMs use to interrupt down uncooked textual content into their atomic items – i.e., tokens – that are widespread sequences of characters present in a set of textual content. To that finish, the textual content enter is transformed into their numerical illustration and fed to the mannequin.
LLMs work by understanding the statistical relationships between these tokens, and produce the following token in a sequence of tokens. The output tokens are detokenized to human-readable textual content by mapping them to their corresponding phrases utilizing the tokenizer’s vocabulary.

The assault method devised by HiddenLayer targets the tokenization technique to bypass a textual content classification mannequin’s capability to detect malicious enter and flag security, spam, or content material moderation-related points within the textual enter.
Particularly, the synthetic intelligence (AI) safety agency discovered that altering enter phrases by including letters in sure methods precipitated a textual content classification mannequin to interrupt.
Examples embrace altering “directions” to “finstructions,” “announcement” to “aannouncement,” or “fool” to “hidiot.” These small modifications trigger the tokenizer to separate the textual content otherwise, however the which means stays clear to each the AI and the reader.
What makes the assault notable is that the manipulated textual content stays absolutely comprehensible to each the LLM and the human reader, inflicting the mannequin to elicit the identical response as what would have been the case if the unmodified textual content had been handed as enter.
By introducing the manipulations in a method with out affecting the mannequin’s capability to grasp it, TokenBreak will increase its potential for immediate injection assaults.
“This assault method manipulates enter textual content in such a method that sure fashions give an incorrect classification,” the researchers stated in an accompanying paper. “Importantly, the top goal (LLM or e mail recipient) can nonetheless perceive and reply to the manipulated textual content and subsequently be weak to the very assault the safety mannequin was put in place to forestall.”

The assault has been discovered to achieve success towards textual content classification fashions utilizing BPE (Byte Pair Encoding) or WordPiece tokenization methods, however not towards these utilizing Unigram.
“The TokenBreak assault method demonstrates that these safety fashions might be bypassed by manipulating the enter textual content, leaving manufacturing methods weak,” the researchers stated. “Understanding the household of the underlying safety mannequin and its tokenization technique is vital for understanding your susceptibility to this assault.”
“As a result of tokenization technique sometimes correlates with mannequin household, an easy mitigation exists: Choose fashions that use Unigram tokenizers.”
To defend towards TokenBreak, the researchers counsel utilizing Unigram tokenizers when doable, coaching fashions with examples of bypass tips, and checking that tokenization and mannequin logic stays aligned. It additionally helps to log misclassifications and search for patterns that trace at manipulation.
The examine comes lower than a month after HiddenLayer revealed the way it’s doable to use Mannequin Context Protocol (MCP) instruments to extract delicate knowledge: “By inserting particular parameter names inside a instrument’s perform, delicate knowledge, together with the total system immediate, might be extracted and exfiltrated,” the corporate stated.

The discovering additionally comes because the Straiker AI Analysis (STAR) crew discovered that backronyms can be utilized to jailbreak AI chatbots and trick them into producing an undesirable response, together with swearing, selling violence, and producing sexually specific content material.
The method, known as the Yearbook Assault, has confirmed to be efficient towards varied fashions from Anthropic, DeepSeek, Google, Meta, Microsoft, Mistral AI, and OpenAI.
“They mix in with the noise of on a regular basis prompts — a unusual riddle right here, a motivational acronym there – and due to that, they usually bypass the blunt heuristics that fashions use to identify harmful intent,” safety researcher Aarushi Banerjee stated.
“A phrase like ‘Friendship, unity, care, kindness’ does not increase any flags. However by the point the mannequin has accomplished the sample, it has already served the payload, which is the important thing to efficiently executing this trick.”
“These strategies succeed not by overpowering the mannequin’s filters, however by slipping beneath them. They exploit completion bias and sample continuation, in addition to the way in which fashions weigh contextual coherence over intent evaluation.”